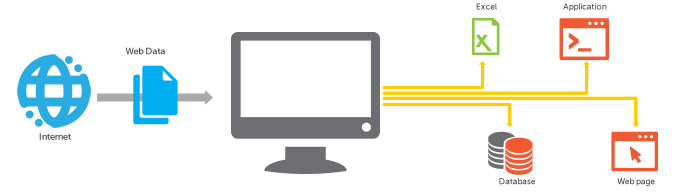
Screen scraping is normally associated with the programmatic collection of visual data from a source, instead of parsing data as in Web scraping. Originally, screen scraping referred to the practice of reading text data from a computer display terminal’s screen. This was generally done by reading the terminal’s memory through its auxiliary port, or by connecting the terminal output port of one computer system to an input port on another. The term screen scraping is also commonly used to refer to the bidirectional exchange of data. This could be the simple cases where the controlling program navigates through the user interface, or more complex scenarios where the controlling program is entering data into an interface meant to be used by a human. More modern screen scraping techniques include capturing the bitmap data from the screen and running it through an OCR engine, or for some specialized automated testing systems, matching the screen’s bitmap data against expected results. This can be combined in the case of GUI applications, with querying the graphical controls by pro-grammatically obtaining references to their underlying programming objects.